公司新闻
tensorflow中model.compile()
里面的具体参数有:
我们一帮需要设置的就只有前三个参数,
没有衰减率的一般是在整个更新过程中学习率不改变,有衰减率的就是自适应学习率的优化器,就是在更新参数过程中,学习率能根据梯度自己改变。
这里的学习率改变好像是针对的这一轮中的学习率,在下一个epoch中学习率又会变成没变化之前的值。例如某一轮的学习率为0.001,在这一轮训练过程中学习率可能会变化,但是下一轮开始时学习率是0.001,也就是变化不带入下一轮训练,如果想要改变学习率,就在回调函数里设置学习率衰减方式才能改变 (不知道我说的对不对,我也不是很明白,有错误的话请大哥批评指正 )
tf.keras.optimizers中有很多优化器供我们选择:
- tf.keras.optimizers.Adadelta
- tf.keras.optimizers.Adagrad
- tf.keras.optimizers.Adam
Adam优化是一种基于一阶和二阶矩自适应估计的随机梯度下降方法。
根据Kingma et al.,2014的说法,该方法“计算效率高,几乎不需要内存,对梯度的对角线重新缩放不变性,非常适合于数据/参数较大的问题”。
- tf.keras.optimizers.RMSprop
利用了梯度的均方
- tf.keras.optimizers.SGD
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。缺点还挺大的,
- tf.keras.losses.BinaryCrossentropy为二分类交叉熵损失函数
计算公式为:
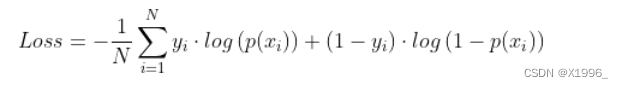
yi为第i个的真实标签,p(xi)为第i个预测正确的概率,当输出的预测值不是概率时,我们需要将from_logits参数设置为True,它会将预测值转换为概率,如果预测值是概率的话,就设置为False。

输出:

2. tf.keras.losses.BinaryFocalCrossentropy
Focal loss主要用来解决样本不均衡问题,引入了一个聚焦因子和loss相乘。
如果真实标签为1,聚焦因子为 focal_factor = (1 - output) ^ gamma
如果真是标签为0,聚焦因子为 focal_factor = ( output) ^ gamma
output为输出概率:
当gamma为0时,就成了BinaryCrossentropy。
参数:
具体实现过程:
输出:

3. tf.keras.losses.CategoricalCrossentropy 多分类交叉熵损失函数
当y_true为One-Hot 编码时使用CategoricalCrossentropy
当y_true为整数编码时使用SparseCategoricalCrossentropy

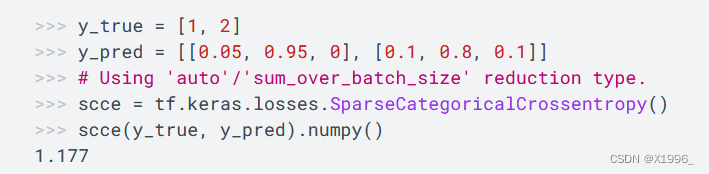
还有很多其他损失函数。。。。。
常用的分类指标有准确率、精度等,添加进去就会在训练过程中实时打印这些指标。
metrics=[tf.keras.metrics.Accuracy(),tf.keras.metrics.Precision()]
例外也可以自定义一些函数添加进去,例如想打印学习率:
这样就可以打印了。
tensorflow的API里函数太多了。。。。。
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

