公司新闻
CUDA基本优化方法
一、基于编程模型和执行模型的优化方法
1.选取合适的gridDim和blockDim
blockDim最好为32的整数倍:因为执行指令的基本单位为线程束,线程束内的所有线程统一执行广播下来的命令,而线程束的线程数量基本为32。当block被分到SM中去,其会被划分为多个线程束,若blockDim!=线程束内线程数整数倍,则会造成线程的浪费。
2.减少存在分支的if
因为线程束中的所有线程执行同一条的指令,若出现存在出现分支的if,即线程束内的部分线程符合if条件,部分符合else条件,因cuda编译不具备分支预测能力,则会在一个指令执行if,下一个指令执行else,两个指令中都有部分不符合条件的线程空闲,从而造成浪费,如下述代码所示:
线程束内奇数线程(threadIdx.x为奇数)会执行else,偶数线程执行if,分化很严重。对此,我们可以更改if条件,使整个线程束内都符合if或else即可:
可以得到相同但是错乱的结果C,这个顺序是无所谓的,可以后期调整。
3.循环展开
减少循环判断的次数,本质上也是减少分支
最新的cuda应该不需要手动展开了,在for前加上#pragma unroll 循环次数命令即可。
二、基于内存的优化方法

1.合并访问和对齐访问
核函数运行时需要从全局内存(DRAM)中读取数据,只有两种粒度:128字节、32字节。粒度可以理解为最小单位,也就是核函数运行时每次读内存,哪怕是读一个字节的变量,也要读128字节,或者32字节。
合并访问是指所有线程访问连续的对齐的内存块,对于L1 cache,内存块大小支持32字节、64字节以及128字节为单位读取数据。前提是,访问必须连续,并且访问的地址是以32字节对齐。
我们把一次内存请求——也就是从内核函数发起请求,到硬件响应返回数据这个过程称为一个内存事务。当一个内存事务的首个访问地址是缓存粒度(32或128字节)的偶数倍的时候:比如二级缓存32字节的偶数倍64,128字节的偶数倍256的时候,这个时候被称为对齐内存访问。

规约中可以通过设计累加的位置来实现合并对齐访问,提高效率
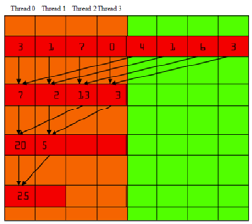
2.利用缓存来进行交叉访问(非合并的访问)
在某些情况下,无法避免进行交叉的读或写,如求矩阵的转置。这种情况下可以利用从缓存中读取的高效性,进行交叉内存访问(虽然按照列读是不合并的,但是使用一级缓存加载过来的数据在后面会被使用,虽然一级缓存一次读取128字节的数据,其中只有一个单位是有用的,但是剩下的并不会被马上覆盖,粒度是128字节,但是一级缓存的大小有几k或是更大,这些数据很有可能不会被替换,所以,我们按列读取数据,虽然第一行只用了一个,但是下一列的时候,理想情况是所有需要读取的元素都在一级缓存中,这时候,数据直接从缓存里面读取),从而让写结果到全局内存的过程是合并访问(写的过程不走缓存)。
3.基于共享内存的优化
共享内存是在他所属的线程块被执行时建立,线程块执行完毕后共享内存释放,线程块和他的共享内存有相同的生命周期。
共享内存读写速度较快,且可编程,故可用它来存储中间变量,或者先将内存中的数据读到共享内存中来,再做后续的操作。
共享内存按列读取不会导致交叉访问那么严重的延迟,代码中申请了共享内存来进行交叉访问,避免了交叉的全局内存访问,还对申请的动态内存做了填充,防止读取冲突(有疑问)。
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

