公司新闻
(五)最优化建模与算法之无约束优化
很多无约束优化问题的算法思想可以推广到其他优化问题上,因此掌握如何求解无约束优化问题 的方法是设计其他优化算法的基础。无约束优化考虑如下问题:
无约束优化问题是无需可虑可行域,对于光滑函数,利用梯度和海森矩阵设计算法;对于非光滑函数,利用次梯度来构造迭代方程。
无约束优化问题的优化算法主要分为两大类:线搜索类型的优化算法和信赖域类型的优化算法。它们都是对目标函数在局部进行近似,但处理近似问题的方式不同。
- 线搜索类算法:根据搜索方向的不同可以分为梯度类算法、次梯度算法、牛顿算法、拟牛顿算法等。一旦确定了搜索的方向,下一步即沿着该方向寻找下一个迭代点;
- 信赖域算法:主要针对目标函数二阶可微的情形,它是在一个给定的区域内使用二阶模型近似原问题,通过不断直接求解该二阶模型从而找到最优值点。
接下来,介绍这些算法的基本思想和执行过程,并简要分析它们的重要性质。
线搜索类算法的数学表述为:给定当前迭代点,首先通过某种算法确定下降方向向量(搜索方向,保证此方向搜索目标函数值减小),之后确定正数(步长),则下一步的迭代点可写成:
线搜索类算法的核心是选取搜索方向与确定步长。由于步长的选择在不同算法中相对一致,首先介绍步长的选取方法。首先构建辅助函数如下: 考虑到目标函数下降量和计算量,步长可以通过下式来确定:
上式计算的是最佳步长,对应的搜索算法称为精确线搜索算法。计算精确搜索步长往往需要很大计算量,因此实际中,通常对上式进行松弛,要求步长满足某些不等式性质即可,此类方法结构简单,称为非精确线性搜索。在非精确线搜索算法中,选择步长需要满足一定要求,这些要求称为线搜索准则。线搜索准则的合适与否直接决定了算法的收敛性。
Armijo 准则:引入Armijo准则的目的是保证每一步迭代充分下降。方向为下降方向,满足下式: 上式的几何含义是,步长和函数值构成坐标点位于下式直线的下方
如下图所示,图中标明的点都满足Armijo准则。
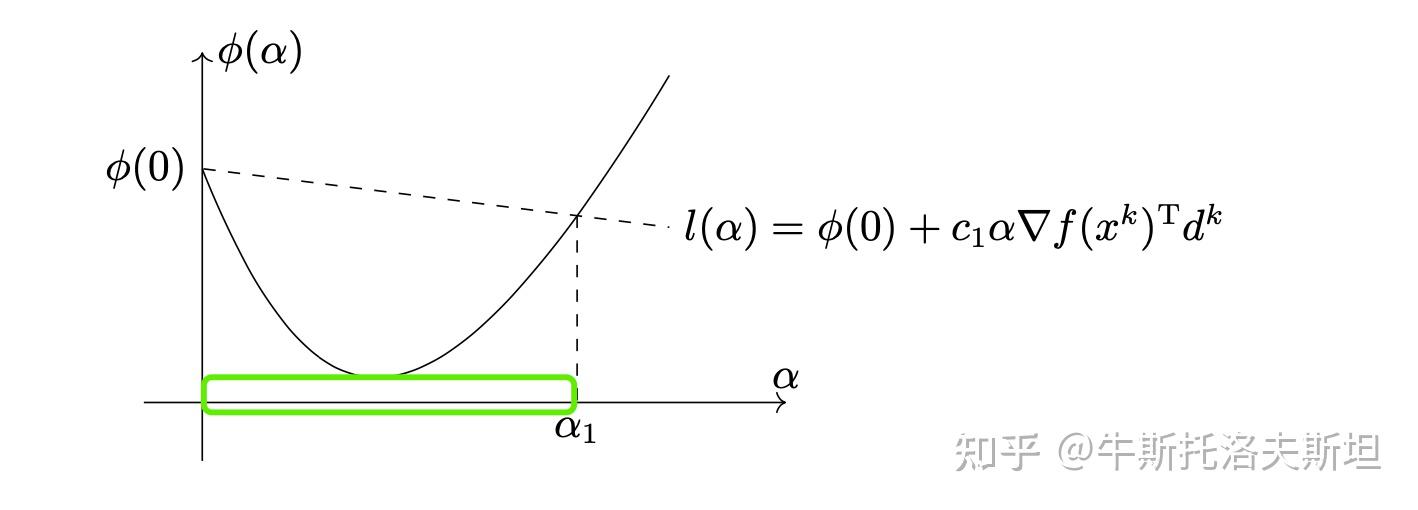
Armijo 准则并不能保证迭代的收敛性,如步长为0时满足准则,但迭代序列中的点固定不变,因此Armijo 准则需要配合其他准则共同使用。在优化算法的实现中,寻找一个满足Armijo 准则的步长是比较容易的, 一个最常用的算法是回退法。
回退法:给定初值步长,不断以指数方式缩小试探步长,找到第一个满足Armijo 准则的点,如下 其基本过程如下所示:

该算法被称为回退法是因为步长的试验值是由大至小的,它可以确保输出的步长能尽量地大满足Armijo 准则。当步长足够小时,Armijo 准则总能成立,在实际中,给步长设置一个下界,防止步长过小。
为了克服Armijo 准则的缺陷,需要引入其他准则来保证每一步的步长不会太小。Armijo 准则限制了点在一直线下方,再加上点必须再另一条直线的上方,防止步长过小,即Armijo-Goldstein 准则,简称Goldstein 准则。
Goldstein 准则:步长满足下式 同理其几何含义为点必须在两条直线之间,如下图所示:
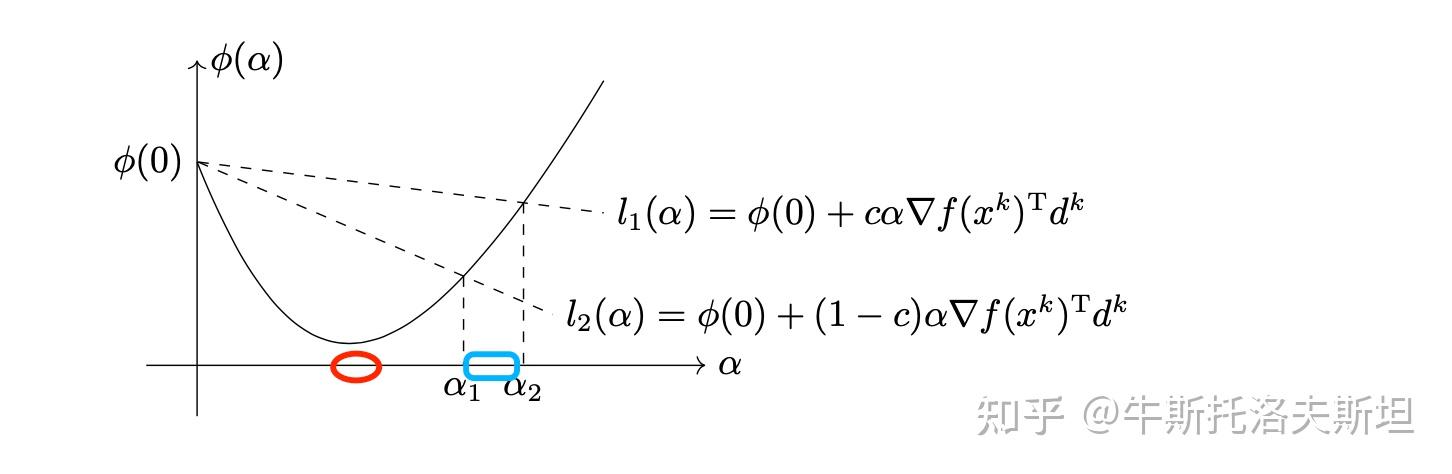
Goldstein 准则能够使得函数值充分下降,但是它可能避开了最优的函数值,如上图所示最有步长不在Goldstein 准则确定的范围内。为此我们引入Armijo-Wolfe 准则,简称Wolfe 准则。
Wolfe 准则:步长满足下两式
其几何意义是,第一个不等式为Armijo准则约束,第二个等式约束要求步长对点的斜率不能小于0处点斜率的 倍。Wolfe 准则在绝大多数情况下会包含线搜索子问题的精确解.在实际应用中,参数
通常取为0.9。如下图所示。

以上介绍的三种准则都有一个共同点:使用这些准则产生的迭代点列都是单调的。在实际应用中,非单调算法有时会有更好的效果。
Grippo准则:属于非单调线搜索准则,步长满足下式 此准则与Armijo 准则非常相似,区别在于Armijo 准则要求下一次迭代的函数值比本次迭代的函数值有充分下降,而Grippo准则只需要下一步函数值相比前面至多M 步以内迭代的函数值有下降就可以了,相当于Armijo 准则的松弛,也不要求函数值的单调性, 可以节省很多搜索次数与函数计算次数。

梯度类算法,其本质是仅仅使用函数的一阶导数信息选取下降方向。最基本的算法是梯度下降法,即直接选择负梯度作为下降方向。梯度下降法的方向选取非常直观,实际应用范围非常广,因此它在优化算法中的地位可相当于高斯消元法在线性方程组算法中的地位。
将辅助函数式(3),泰勒展开为 根据柯西不等式,当步长足够小时,下降方向选择负梯度方向函数下降最快,得到梯度下降方法的迭代方程如下:
步长的选取依赖于线性搜索方法算法,也可以直接固定步长。
为了直观地理解梯度法的迭代过程,以二次函数为例来展示该过程,其迭代示意图如下图所示。
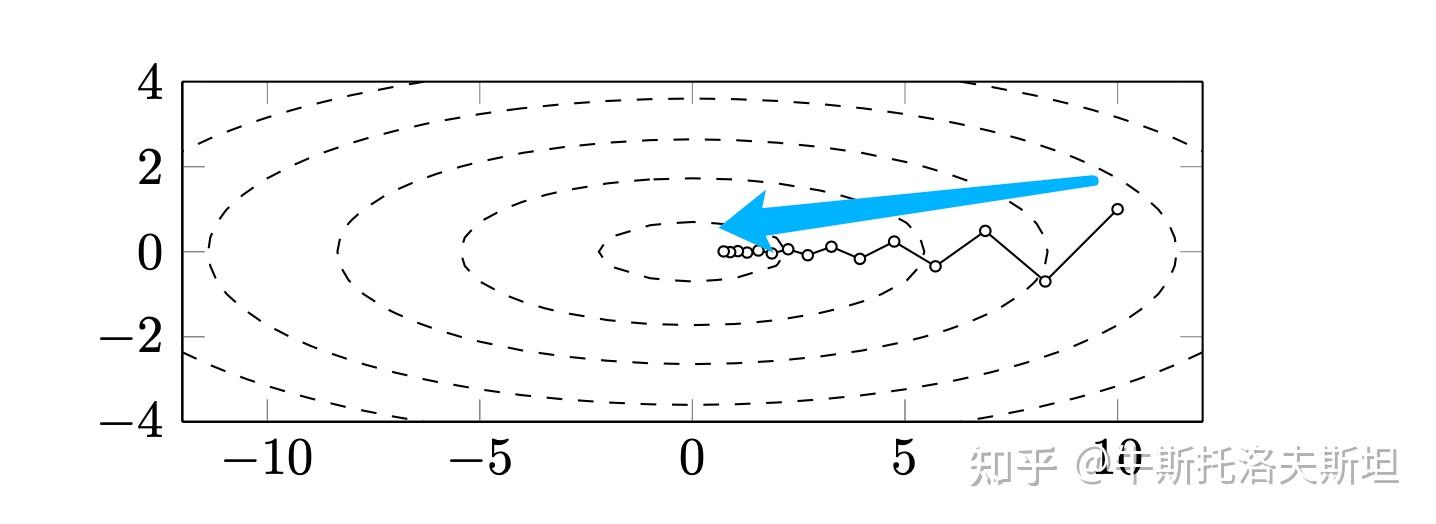
当问题的条件数很大,也即问题病态时,梯度下降法的收敛性质会受到很大影响。Barzilai-Borwein (BB) 方法是一种特殊的梯度法,经常比一般的梯度法有着更好的效果。其下降方向仍为负梯度方向,但步长不是有线性搜索算法给出的,其迭代格式为 其中步长可以用下式中的一个来计算:
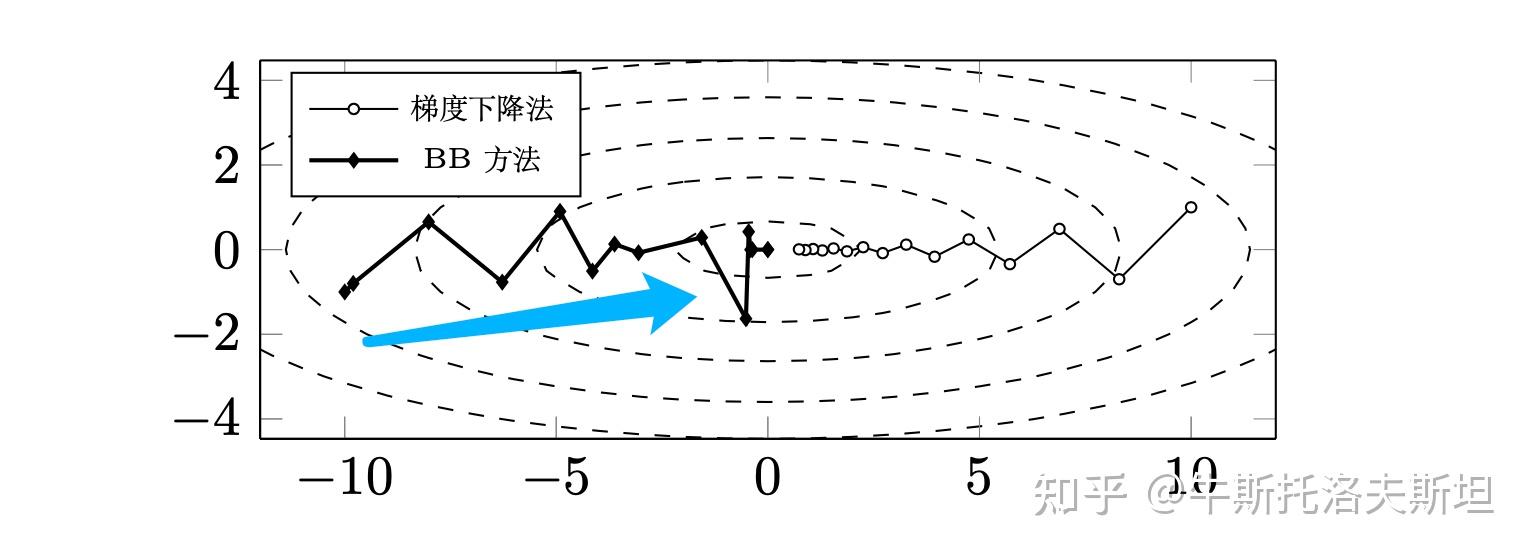
计算两种BB 步长的任何一种仅仅需要函数相邻两步的梯度信息和迭代点信息,不需要任何线搜索算法即可选取算法步长。因为这个特点,BB 方法的使用范围特别广泛。实际用式(15)或(16)计算出的步长可能过大或过小,因此可以对步长做如下上下界约束: BB 方法是非单调方法,有时也配合非单调收敛准则使用以获得更好的实际效果,BB方法的计算流程如下所示。

对二次函数使用BB法和梯度下降法的对比如下图所示。
LASSO (least absolute shrinkage and selection operator)问题的原始形式为: 上述目标函数在某些点无法计算梯度。因此不能利用梯度法对其进行求解。考虑到目标函数的不光滑项为绝对值函数,它实际上是 各个分量绝对值的和,如果能找到一个光滑函数来近似绝对值函数,那么梯度法就可以被用在上述问题的求解。实际考虑如下光滑函数:
上式为实际上是Huber 损失函数的一种变形,当参数
时,光滑函数和绝对值函数越来越接近,如下图所示。
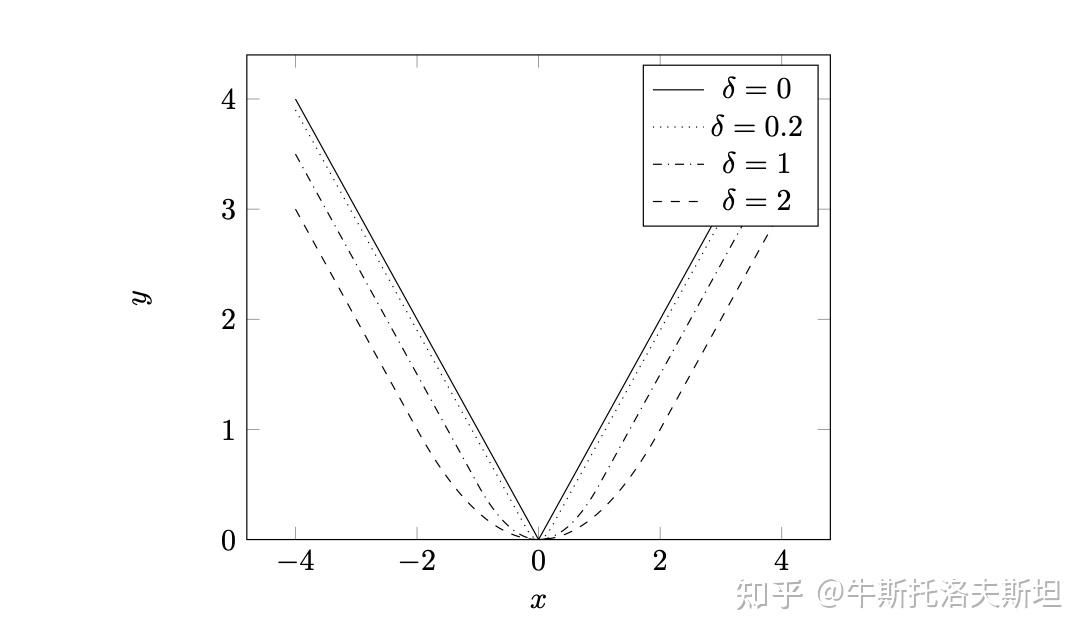
因此构造光滑LASSO问题如下: 由此计算目标函数梯度,可以进行梯度法求解。不同正则化因子,对应的求解迭代过程,如下图所示。

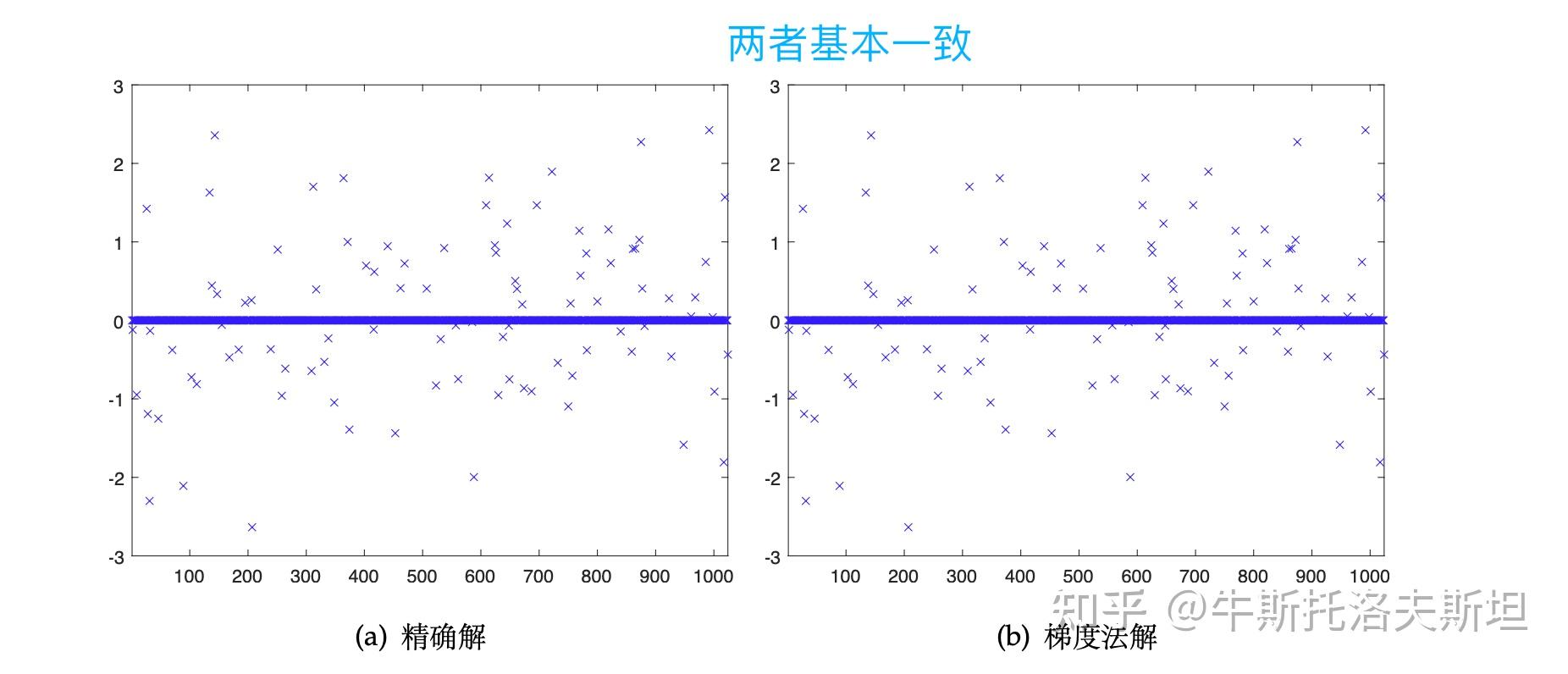
光滑化梯度法在400 步左右收敛到LASSO 问题的解,收敛解与精确解的对比如下图所示。
次梯度法是求解凸函数最优化(凸优化)问题的一种迭代法。次梯度法能够用于不可微的目标函数。当目标函数可微时,对于无约束问题次梯度法与梯度下降法具有同样的搜索方向。梯度下降法,使用该方法的前提为目标函数是一阶可微的。在实际应用中经常会遇到不可微的函数,对于这类函数无法在每个点处求出梯度,但往往它们的最优值都是在不可微点处取到的。为了能处理这种情形,这一节介绍次梯度算法。
假设目标函数为凸函数,但不一定可微。类比梯度法的构造,如下次梯度算法的迭代格式: 次梯度算法有其独特性质:
- 次微分是一个集合,在次梯度算法的构造中只要求从这个集合中选出一个次梯度即可,但在实际中 不同的次梯度取法可能会产生截然不同的效果;
- 因为0在次梯度集合里面,因此梯度充分小的收敛条件不能应用于次梯度算法的停止条件;
- 步长选取在次梯度法中的影响非常大。
同样选择LASSO问题,可以得到其一个次梯度为 得到次梯度算法的迭代公式为
步长对优化的影响如下图所示。
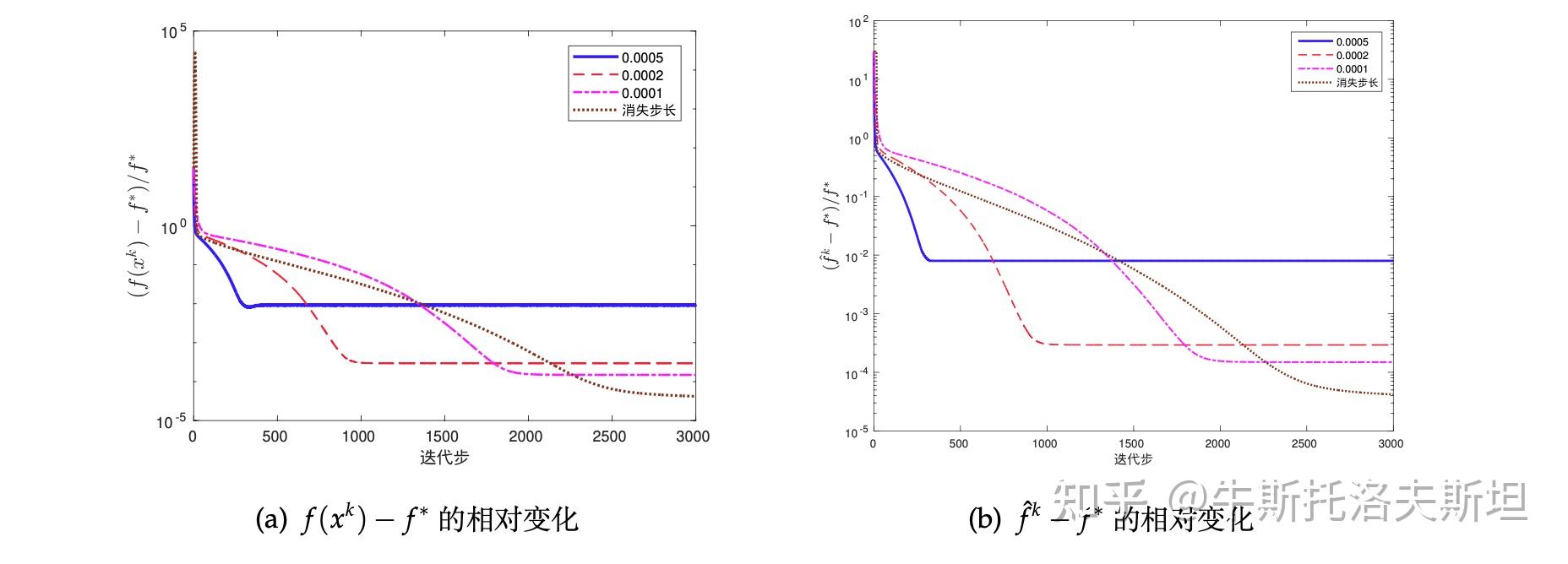
可以看出步长设定对收敛影响很大,收敛比上一节中的光滑化梯度法慢一些。
梯度法仅仅依赖函数值和梯度的信息(即一阶信息),如果函数充分光滑,则可以利用二阶导数信息构造下降方向。牛顿类算法就是利用二阶导数信息来构造迭代格式的算法。由于利用的信息变多,牛顿法的实际表现可以远好于梯度法,但是它对函数的要求也相应变高。
对于二次连续可微函数,考虑函数在迭代点处的二阶泰勒展开为 忽略高阶项,并求其稳定点,得到牛顿方程如下:
当上式中矩阵为非奇异时,可求得更新方式构造出经典牛顿迭代方程为
上式默认步长为1,即可以不额外考虑步长的选取。
经典牛顿法是收敛速度很快的算法,其收敛条件为:初始点必须距离问题的解充分近,即牛顿法只有局部收敛性;海瑟矩阵需要为正定矩阵。
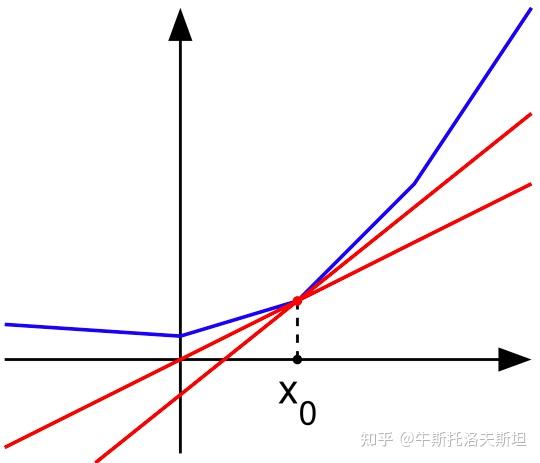
对于病态问题,牛顿法的收敛域可能会变小,这对初值选取有了更高的要求。牛顿法适用于优化问题的高精度求解,但它没有全局收敛性质。因此在实际应用中,人们通常会使用梯度类算法先求得较低精度的解,而后调用牛顿法来获得高精度的解。
蓝线表示方程而红线表示切线。可以看出比更靠近所要求的根。
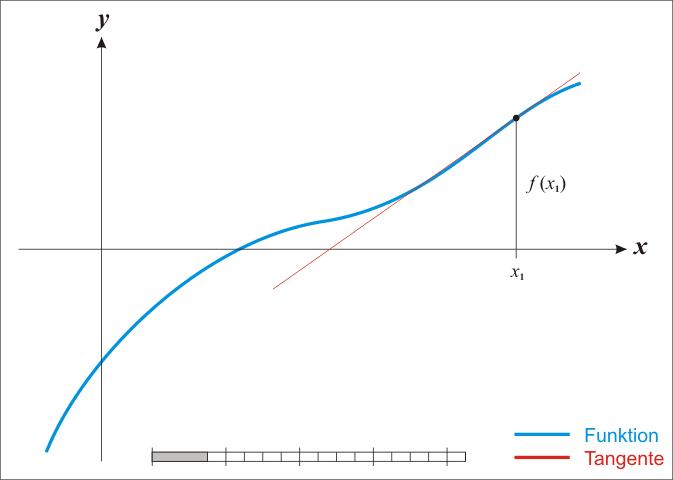
经典牛顿法有如下缺陷:
- 每一步迭代需要求解一个n维线性方程组,这导致在高维问题中计算量很大;
- 海森矩阵既不容易计算又不容易储存;
- 海森矩阵不正定时,牛顿方程求得方向性质通常比较差;
- 当迭代点距最优值较远时,直接选取步长为1时,会使得迭代极其不稳定,在有些情况下迭代点列会发散。
为了克服这些缺陷,对经典牛顿法做出某种修正或变形,使其成为真正可以使用的算法。这里介绍带线搜索的修正牛顿法,其基本思想是修正海森矩阵使其正定;引入线性搜索改善算法稳定性,一般修正牛顿算法计算流程如下图所示:

常用的非精确牛顿法是牛顿共轭梯度法,即使用共轭梯度法求解牛顿方程。由于共轭梯度法在求解线性方程组方面有不错的表现,因此只需少数几步(有时可能只需要一步)迭代。在多数问题上牛顿共轭梯度法都有较好的数值表现,该方法已经是求解优化问题不可少的优化工具。
共轭梯度法:(Conjugate gradient method),是求解系数矩阵为对称正定矩阵的线性方程组的数值解的方法。共轭梯度法是一个迭代方法,它适用于系数矩阵为稀疏矩阵的线性方程组,因为使用像Cholesky分解这样的直接方法求解这些系统所需的计算量太大了。这种方程组在数值求解偏微分方程时很常见。
其计算流程如下所示:

拟牛顿法能够在每一步以较小的计算代价生成近似矩阵,并且使用近似矩阵代替海瑟矩阵而产生的迭代序列仍 具有超线性收敛的性质。
割线方程:将牛顿方程中的海森矩阵用其近似(易于计算)矩阵代替如下 或者其逆的近似矩阵满足方程
曲率条件:近似矩阵需满足正定性是一个很关键的因素,其必要条件为
拟牛顿方法的一般计算框架为:

在实际应用中基于逆近似矩阵的拟牛顿方法更加实用,因为不需要求解线性方程组,而这一步骤在大规模问题上是非常耗时的。但近似矩阵的拟牛顿法有比较好的理论性质,产生的迭代序列比较稳定。如果有办法快速求解线性方程组,我们也可采用基于近似矩阵的拟牛顿法。此外在某些场景下,比如有些带约束的优化问题的算法设计,由于需要用到海森矩阵的近似,近似矩阵的使用也很常见。
秩一更新:秩一更新(SR1) 公式是结构最简单的拟牛顿矩阵更新公式。使用待定系数法求出修正矩阵,并设 根据割线方程式(26),整理得到最终的更新公式:
同理可以得到逆矩阵的更新公式为
SR1 公式虽然结构简单,但是有一个重大缺陷:它不能保证矩阵在迭代过程中保持正定。因此在实际中较少使用。
为了克服SR1 公式的缺陷,现在考虑对近似矩阵的秩二更新。BFGS 公式,它是由Broyden,Fletcher,Goldfarb,Shanno 四人名字的首字母组成。同样地,采用待定系数法来推导此公式。
设更新公式为 根据牛顿方程,代入上式整理得到BFGS 公式 更新公式
其中定义:
同理可以得到逆矩阵的更新公式:
上式为下式优化问题的解:
其中:
这个优化问题的含义是在满足割线方程的对称矩阵中找到离当前矩阵最近的矩阵H。BFGS 公式是目前最有效的拟牛顿更新方式之一,它有比较好的理论性质,实现起来也并不复杂。
使用 Rosenbrock 函数(“香蕉函数”)运行 BFGS 方法的示例:
对式(35)进行改动可得到有限内存BFGS 格式(L-BFGS),它是常用的处理大规模优化问题的拟牛顿类算法。
在BFGS 公式的推导中,如果利用割线方程对 推导秩二修正的拟牛顿修正,我们将得到基于Hk 的拟牛顿矩阵更新:
这种迭代格式首先由Davidon 发现,此后由Fletcher 以及Powell 进一步发展,因此被称为DFP 公式。尽管DFP 格式在很多方面和BFGS 格式存在对偶关系,但从实际效果来看,DFP 格式整体上不如BFGS 格式。因此在实际使用中人们更多使用BFGS 格式。
拟牛顿法虽然克服了计算海瑟矩阵的困难,但是它仍然无法应用在大规模优化问题上。主要因为拟牛顿矩阵或逆矩阵为稠密矩阵,存储矩阵消耗的内存,这对于大规模问题显然是不可能实现的,L-BFGS解决了这一存储问题,从而使得人们在大规模问题上也可应用拟牛顿类方法加速迭代的收敛。L-BFGS 双循环递归算法如下:
考虑基匹配追踪问题:
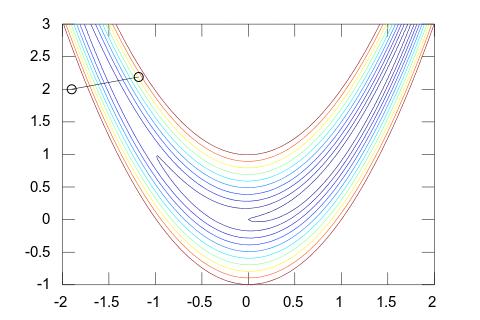
当靠近最优解时,L-BFGS 方法的迭代点列呈 Q-线性收敛,如下图所示。

考虑逻辑回归问题, 调用 L-BFGS(内存长度取为 5), 其迭代收敛过程如下图所示。

信赖域算法(Trust-region methods)和线搜索算法都是借助泰勒展开来对目标函数进行局部近似,但它们看待近似函数的方式不同。在线搜索算法中,先利用近似模型求出下降方向,然后给定步长;而在信赖域类算法中,直接在一个有界区域内求解这个近似模型,而后迭代到下一个点。因此信赖域 算法实际上是同时选择了方向和步长。
根据带拉格朗日余项的泰勒展开, 类似牛顿法,二阶近似为
对上式可行域增加约束, 即信赖域:
信赖域算法每一步都需要求解 如下子问题:
下图显示了上式的求解过程,图中实线表示目标函数的等高线,虚线代表
的等高线,
表示求解无约束问 题得到的下降方向,
示求解信赖域上式得到的下降方向。信赖域算法正是限制了
的大小,使得迭代更加保守,因此可以在牛顿方向很差时发挥作用 。

其计算流程如下:

Steihaug 在 1983 年对共轭梯度法进行了改造,使其成为能求解问题信赖子问题的算法。此算法能够应用在大规 模问题中,是一种非常有效的信赖域子问题的求解方法, 其计算流程如下所示。

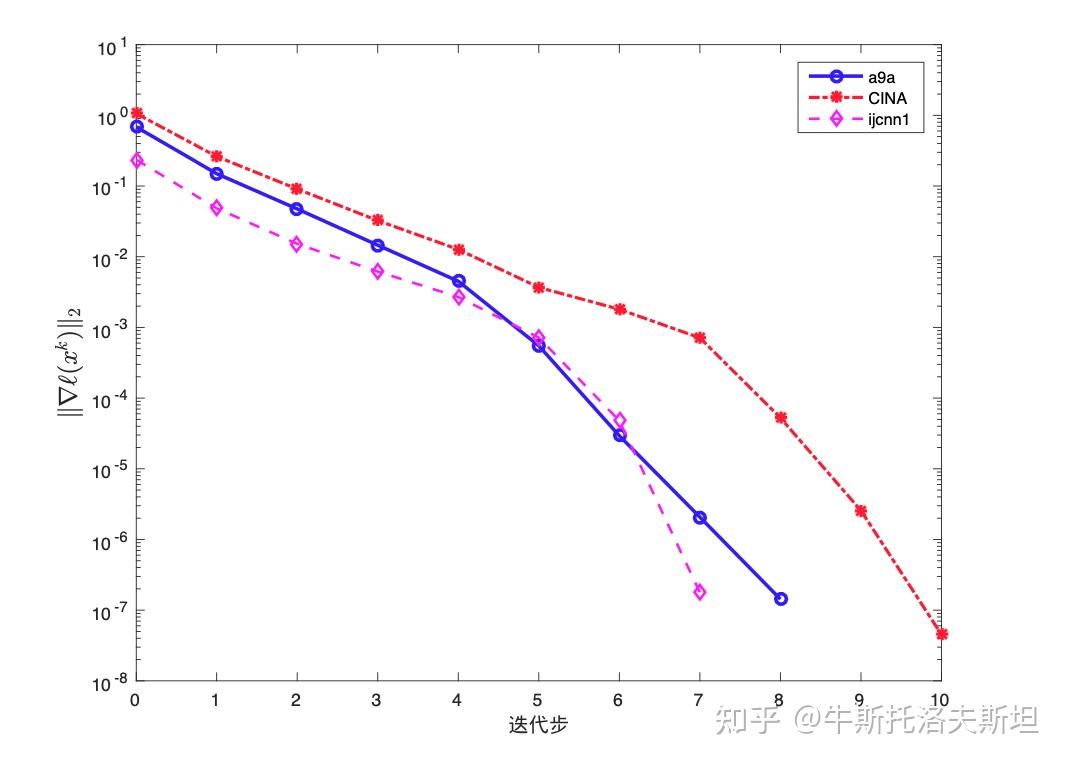
考虑逻辑回归问题: 在不同数据集上应用信頼域求解收敛过程如下图所示。从图中可以看到,在精确解附近梯度范数具有Q-超线性收敛性质。
非线性最小二乘问题是一类特殊的无约束优化问题,它有非常广泛的实际应用背景。
考虑非线性最小乘问题一般形式如下: 其中
为光滑函数,并且
,
为残差。定义残差向量如下:
目标函数的梯度与海森矩阵如下:
其中为
在点
处的雅克比矩阵。
直接使用 作为海瑟矩 阵的近似矩阵来求解牛顿方程,其下降方向为:
上述方程为如下线性最小二乘问题的最优性条件:
高斯 – 牛顿法的框架如下:

Levenberg-Marquardt (LM) 方法是由 Levenberg 在 1944 年提出的求 解非线性最小二乘问题的方法 。它本质上是一种信赖域型方法。主要应用场合为当矩阵奇异时,它仍然能给出一个下降方向。LM 方法每一步求解如下子问题:
信赖域型 LM 方法本质上是固定信赖域半径,每一步迭代需要求解线性方程组求得
:
这个求解过程在 LM 方法中会占据相当大的计算量。因此基于
更新的 LM 方法也被称为 LMF 方法,即 每一步求解子问题:
我们引 入如下定义来衡量近似程度的好坏如下式:
LMF 算法的框架如下所示:

和 LM 方法相比,LMF 方法每一次迭代只需要求解一次 LM 方程,从 而极大地减少了计算量,在编程方面也更容易实现.所以 LMF 方法在求解 最小二乘问题中是很常见的做法。
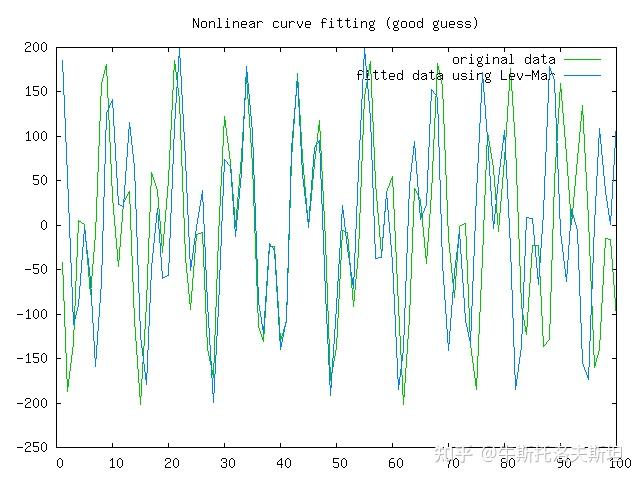
一个非线性曲线拟合的例子如下:
高斯 – 牛顿法和 LM 方法,这两个算法针对 小残量最小二乘问题十分有效。而在大残量问题中,海瑟矩阵的第 二部分的作用不可忽视,仅仅考虑作为第 k 步的海瑟矩阵近似则会带来很大误差。海瑟矩阵表达式由两部分组成:一部分容易得出,但不精确; 另一部分较难求得,但在计算中又必不可少。对于容易部分可以直接保留高斯 – 牛顿矩阵,而对于较难部分则可以利用拟牛顿法来进行近似。即用下式近似海森矩阵:
如何构造 和拟牛顿方法计算基本一样,这里就不介绍了。
介绍了无约束优化的各种基础算法,希望到遇到实际问题时,可以进行查阅。
[1]. 维基百科。
[2]. 刘浩洋等《最优化:建模、算法与理论》。
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

