行业新闻
pytorch系列13 ---优化算法optim类
本文主要讲解pytorch中的optim累以及lr_schdule类和optim优化器的配置,使用方法。
在https://blog.csdn.net/dss_dssssd/article/details/83892824中提及优化算法的使用步骤,
-
先初始化
-
反向传播更新参数
- 将上次迭代计算的梯度值清0
- 反向传播,计算梯度值
- 更新权值参数
SGD源码: https://pytorch.org/docs/stable/_modules/torch/optim/sgd.html
- 将上次迭代计算的梯度值清0
1. 构造optimizer
1.1 初始化函数:

参数:
-
params: 包含参数的可迭代对象,必须为Tensor
-
其余的参数来配置学习过程中的行为
1.2. per-parameter 选择
不是传入Tensor的可迭代对象,而是传入
的可迭代对象,每一个字典定义一个独立的参数组,每一个必须包含一个键,和一系列与该优化函数对应的参数。
上述代码,中的参数更新使用为的SGD算法,而中的参数更新使用 为 , momentum为的SGD算法
下面用一个两层的线性回归的例子说明一下:
输入为[11, 1], 第一层为[1, 10], 第二层为[10, 1],最后的输出为[11,1]。在优化算法中,第一层和第二层分别使用不同的优化器配置方案。
使用打印出weight和bias,注意函数返回的是迭代器
out:
the first params:
Parameter containing:
tensor([[ 0.7895],
[ 0.4697],
[-0.0534],
[ 0.8223],
[ 0.9414],
[-0.5877],
[-0.4069],
[-0.6598],
[-0.1982],
[-0.2233]], requires_grad=True)
Parameter containing:
tensor([-0.9338, -0.9721, 0.3418, -0.4599, 0.1251, -0.2313, 0.9735, -0.1804,
0.0935, 0.9205], requires_grad=True)
the second params:
[Parameter containing:
tensor([[-0.0765, -0.1632, 0.0979, 0.2206, -0.0102, -0.0452, -0.3096, 0.0189,
-0.0240, -0.0900]], requires_grad=True), Parameter containing:
tensor([-0.1148], requires_grad=True)]
在接收了外部输入的参数params以后,优化器会把params存在self.param_groups里(是一个字典的列表)。每一个字典除了保存参数的[‘params’]键以外,Optimizer还维护着其他的优化系数,例如学习率和衰减率等
out:
[{‘params’: [Parameter containing:
tensor([[ 0.7895],
[ 0.4697],
[-0.0534],
[ 0.8223],
[ 0.9414],
[-0.5877],
[-0.4069],
[-0.6598],
[-0.1982],
[-0.2233]], requires_grad=True), Parameter containing:
tensor([-0.9338, -0.9721, 0.3418, -0.4599, 0.1251, -0.2313, 0.9735, -0.1804,
0.0935, 0.9205], requires_grad=True)], ‘lr’: 0.01, ‘momentum’: 0.9, ‘dampening’: 0, ‘weight_decay’: 0, ‘nesterov’: False},
{‘params’: [Parameter containing:
tensor([[-0.0765, -0.1632, 0.0979, 0.2206, -0.0102, -0.0452, -0.3096, 0.0189,
-0.0240, -0.0900]], requires_grad=True), Parameter containing:
tensor([-0.1148], requires_grad=True)], ‘lr’: 0.001, ‘momentum’: 0.9, ‘dampening’: 0, ‘weight_decay’: 0, ‘nesterov’: False}]
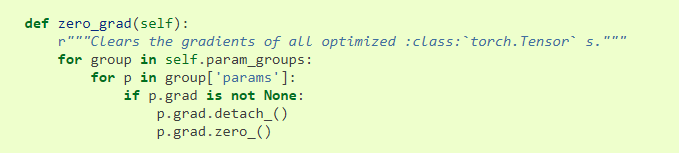
2. optimizer.zero_grade()
在所有的优化算法的基类https://pytorch.org/docs/stable/_modules/torch/optim/optimizer.html中的函数对中的所有的params清零
3. loss.backward()
4. optimizer.step()
4.1. 直接调用step()而不传入参数,大多数优化算法会用这种方法调用ok,因为只涉及到一次调用
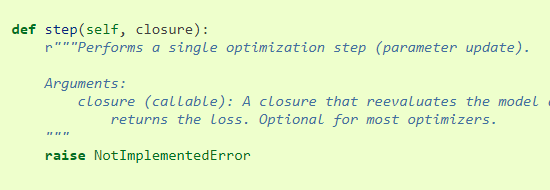
这个方法在Optimizer中是未定义,根据具体的优化器来单独实现。
以下通过SGD类中的函数来说明:
取出每个group中的params进行更新,
将计算的梯度取出,通过weight_decay,momentum,learning_rate等优化器配置方法更新的值,最后赋值给。
4.2 对于Conjugate Gradient 和 LBFGS等优化算法,须有多次评估优化函数,因而要传入来多次计算模型。完成的操作:
- 清楚梯度值
- 计算损失loss
- 返回loss
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

