行业新闻
数值优化算法【1】-- 常用优化算法
很多机器学习和深度学习方法,都是在样本的支持下,利用导数或偏微分寻求方程的解,而传统数学方法中,会用到解析和数值两种解法。
(1)解析解法:
- 就是从小到大教科书里讲的,利用严格公式推导获得解的解析表达式,输入自变量的值就可以求出因变量。
- 如果一个方程或者方程组存在的某些解,是由有限次常见运算(如:分式、三角函数、指数、对数甚至无限级数等)的组合给出的形式,则称该方程存在解析解。
- 例如:对于线性回归模型,采用最小二乘法可以直接得出解析解,
(2)数值解法:
- 当无法由微积分技巧求得解析解时(特别是复杂函数),利用数值分析方式来求得其数值解是比较好的选择。
- 采用某种计算方法(如:有限元方法、数值逼近、插值方法等)得到的解,被称为数值解。
- 数值解是在特定条件下通过近似计算得出来的一个数值。
- 例如:同样对于线性回归模型,采用梯度下降法或牛顿迭代法,可以获得近似的数值解
在机器学习任务中,通过样本集训练求取模型参数,其本质就是求模型参数的解。此类解由于模型复杂可能很难给出解析解的形式,或者由于样本过大解析解法存在计算困难,因此,往往采用数值解法。最典型的案例莫过于深度神经网络,由于隐层层数过多导致模型非常复杂,根本无法获得解析解,只能采用数值解法。
对于机器学习或深度学习问题,通常首先定义一个损失函数,一旦有了损失函数,就可以使用数值解法来尝试最小化损失。 而在最优化理论中,损失函数通常被称为最优化问题的目标函数。 根据传统和惯例,大多数优化算法都与“最小化”有关。 如果我们需要最大化一个目标,有一个简单的解决方案:只要翻转目标函数前面的符号。
虽然最优化为机器学习提供了一种最小化损失函数的方法,但从本质上讲,最优化和机器学习的目标是完全不同的。 前者主要关注训练集上的最小化目标,而后者关注在给定有限数据量的情况下找到合适的模型。 但是,最小化训练误差并不能保证我们找到一组最佳的参数来最小化期望误差。
例如:对于机器学习来说,训练误差和泛化误差一般是不同的:
- 优化算法的目标是减少训练误差
- 机器学习的目标是减少泛化误差。
因此,为了实现后者,除了使用优化算法来减少训练误差外,还需要注意过拟合问题。
机器学习任务中面临许多优化方面的挑战,根据高等数学知识,包括:
对于目标函数 ,如果 处的 值小于 附近任何其他点的 值,则 可以是局部最小值。 如果 在 处的值是目标函数在整个域上的最小值,则 是全局最小值。
例如,给定函数
可以近似这个函数的局部最小值和全局最小值。

机器学习和深度学习模型的目标函数通常具有许多局部最优解。 当优化问题的数值解接近局部最优解时,当目标函数解的梯度下降接近零时,通过最终迭代得到的数值解只可能使目标函数局部最小化,而不是全局最小化。
只有一定程度的噪声才能使参数跳出局部极小值。 事实上,这是随机梯度下降的一个有利性质,在这种情况下,小批量梯度的自然变化,有利于将参数从局部极小值中跳出。
除了局部极小值,鞍部(鞍点)是梯度消失的另一个原因。按照鞍点的定义,目标函数在各个自变量方向上的偏导数在鞍点处趋近于0,但该点处可能既不是全局最小值也不是局部最小值。 考虑下图所示的函数 ,它的一阶导数和二阶导数在 处消失。 优化可能会在某个点停止,但它不是最小值。

更高维度中的鞍点更为隐蔽,如下例所示,考虑函数 。 它的鞍点在 ,这是 的最大值, 的最小值。 它看起来像一个马鞍,这就是这个数学性质的由来。

假设一个函数的输入为 维向量,输出为标量,那么它的海森矩阵有 个特征值。该函数在梯度为0的位置上可能是局部最小值、局部最大值或者鞍点:
- 当函数的海森矩阵在梯度为0的位置上的特征值全为正时,该函数得到局部最小值。
- 当函数的海森矩阵在梯度为0的位置上的特征值全为负时,该函数得到局部最大值。
- 当函数的海森矩阵在梯度为0的位置上的特征值有正有负时,该函数得到鞍点。
随机矩阵理论告诉我们,对于一个大的高斯随机矩阵来说,任一特征值是正或者是负的概率都是0.5。那么,以上第一种情况的概率为 。由于深度学习模型参数通常都是高维的( 很大),目标函数的鞍点通常比局部最小值更常见。在深度学习中,虽然找到目标函数的全局最优解很难,但这并非必要。接下来的几节会逐一介绍深度学习中常用的优化算法,它们在很多实际问题中都能够训练出十分有效的深度学习模型。
高原(梯度消失)问题可能是我们会遇到的最隐秘的问题。 例如:假设我们想最小化函数 ,我们恰好从 开始。 如图所见, 的梯度接近于零,更具体地说是 和 ,梯度接近于0。
高原(梯度消失)问题就好像在内蒙古高原(高损失处)丢一个铁球,它不会因为高海拔而一直滑落,反而会因为出现平原地区而保持静止。平地导致各方向梯度均趋近于0,这种情况也将造成收敛困难。可以认为此时的梯度大小都并没有直接为靠近最优点服务,需要作出优化。这也是在引入ReLU激活函数之前,深度学习模型的训练相当棘手的原因之一。

计算数值解的主要方法来自于最优化理论,最优化理论将问题域大致分为了线性规划问题、非线性规划问题和动态规划问题。目前我们在机器学习和深度学习中常见的最优化方法主要为非线性规划问题,典型优化方法包括常见的无约束条件的最优化方法,如梯度下降法、牛顿法和拟牛顿法、共轭梯度法,以及有约束条件的最优化方法,如:启发式优化方法、拉格朗日乘子法等。
深度学习常用的优化方法大多为无约束的最优化方法,尤其以梯度下降法及其各种变种为主(见下图),而根据是否具备自动计算或调整学习率的能力,又可分为自适应和非自适应两种类型。本系列文章将重点围绕下图所示最优化方法展开。

梯度下降法是最为常用的数值优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解一定是全局解。但一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是将当前位置负梯度方向作为搜索方向(梯度方向为当前位置的最快下降方向,见梯度的定义),所以也称为是”最速下降法“。
梯度下降法的搜索迭代示意图如下图所示:
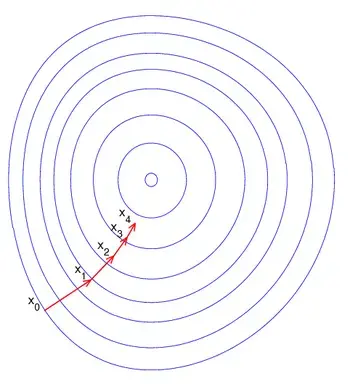
梯度下降法的缺点:
(1)靠近极小值时收敛速度减慢,如下图所示;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降。
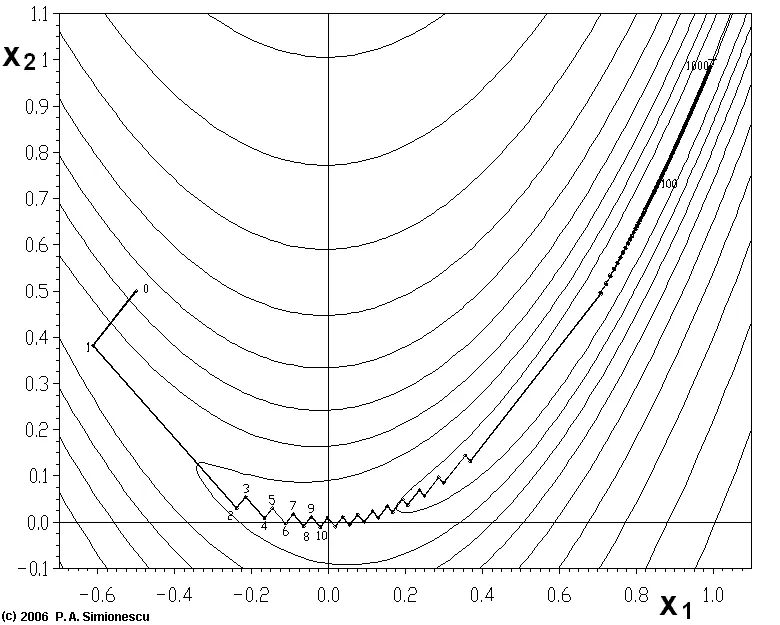
从上图可看出,梯度下降法在接近最优解时收敛速度变慢,利用梯度下降法求解需要很多次的迭代。
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数 的泰勒级数的前面几项来寻找方程 $ f (x)=0$ 的根。牛顿法最大特点就在于它的收敛速度很快。牛顿法的一般步骤如下:
(1)选择一个接近函数 $ f (x)$ 零点的 ,计算相应 和切线斜率 。然后计算穿过点 $(x_0, f (x_0)) $ 并且斜率为 的直线和 轴的交点的 坐标,也就是求如下方程的解:
(2)将新求得的点的 坐标命名为 ,通常 会比 更接近方程 的解。因此可以利用 开始下一轮迭代。迭代公式可化简为如下所示:
(3)已经证明,如果 是连续的,并且待求的零点 是孤立的,那么在零点 周围存在一个区域,只要初始值 位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果 不为0, 那么牛顿法将具有平方收敛的性能。 粗略地说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。下图为一个牛顿法执行过程的例子。由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。
牛顿法搜索动态示例图:

牛顿法和梯度下降法的效率对比:
-
梯度下降法和牛顿法相比,两者都是迭代求解
-
梯度下降法是梯度求解,而牛顿法是用二阶的海森矩阵的逆矩阵求解
-
相对而言,使用牛顿法收敛更快(迭代更少次数),但是每次迭代的时间比梯度下降法长。
-
梯度下降法:
-
牛顿法:
通俗地说:如果想找一条最短路径走到一个盆地的谷底,梯度下降法每次只从当前位置选一个坡度最大的方向走一步,而牛顿法在选择方向时,不仅会考虑当前坡度是否够大,还会考虑走一步之后,坡度是否会变得更大。所以,牛顿法比梯度下降法看得更远一点,能更快地走到最底部。
根据wiki上的解释,几何上牛顿法就是用一个二次曲面去拟合当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前位置的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
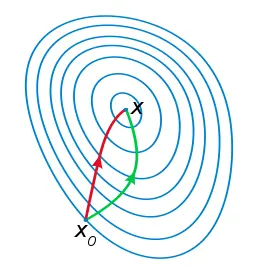
牛顿法的优缺点总结:
- 优点:二阶收敛,收敛速度快;
- 缺点:每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
拟牛顿法的基本想法:牛顿迭代法中需要计算海森矩阵的逆矩阵 ,该计算复杂度高。因此考虑使用一个正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。即考虑用一个 阶正定矩阵 来近似代替 。
拟牛顿法只要求每一步知道目标函数的梯度即可迭代,通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。因为拟牛顿法不需要二阶导数的信息,所以比牛顿法计算效率更高,但又较梯度下降法收敛速度更快。因此,目前优化软件中包含了大量的拟牛顿算法用来解决无约束、约束和大规模数据集的优化问题。
要找到近似的替代矩阵,必定要和 有类似的性质。先看下牛顿法迭代中海森矩阵 满足的条件。
首先 满足以下关系:
取 ,由 $
abla f(x)=g_k + H_k(x-x^{(k)})$ ,得 $ g_{k-1}-g_k=H_k(x^{(k-1)}-x^{(k)}) $ 。
记 $ y_k=g_k-g_{k-1} $ , $ \delta_k=x^{(k)}-x^{(k-1)} $ ,则:
称为拟牛顿条件(Secant equation)。
如果 是正定的( 也是正定的),那么保证牛顿法的搜索方向 是下降方向。这是因为搜索方向是 。由 $x^{(k+1)}=x^{(k)} - H_k^{-1}g_k $ ,有 。
则 在 的泰勒展开可近似为 。
由于 正定,故 。当 为一个充分小的正数时,有 ,即搜索方向 是下降方向。因此拟牛顿法将 作为 近似。要求 满足同样的条件:
- 首先,每次迭代矩阵 是正定的。
- 同时, 满足下面的拟牛顿条件:
按照拟牛顿条件,在每次迭代中可以选择更新矩阵 : $ G_{k+1}=G_k+ \Delta G_k$
这种选择有一定的灵活性,因此有很多具体的实现方法,进而发展出 DFP算法、BFGS算法、Broyden算法 等拟牛顿法。
共轭梯度法是介于梯度下降法与牛顿法之间的一种方法,它仅需利用一阶导数信息,同时克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点。
共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化问题最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。具体的实现步骤请参加 wiki百科共轭梯度法(此处暂略)。
下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
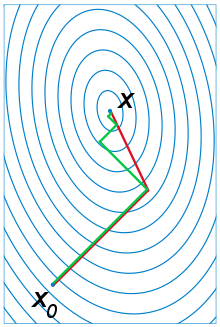
注:绿色为梯度下降法,红色代表共轭梯度法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等。针对多目标优化问题,还有NSGAII算法、MOEA/D算法以及人工免疫算法等。
拉格朗日乘数法主要用于解决约束优化问题,其基本思想是通过引入拉格朗日乘子来将含有 个变量和 个约束条件的约束优化问题转化为含有 个变量的无约束优化问题。拉格朗日乘数法从数学意义入手,通过引入拉格朗日乘子建立极值条件,对 个变量分别求偏导对应了 个方程,然后加上 个约束条件(对应 个拉格朗日乘子)一起构成包含了 个变量的 个方程的方程组问题,这样就能根据求方程组的方法对其进行求解。(此处暂略)
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

