公司新闻
optimizer优化器的选择
最近跑一个框架,结果不理想,在第30个epoch附近AP出现了很大的下降,看tensorboard发现在学习率出了些莫名其妙的问题,于是想把这部分的基础再看一下。
(自己跑的开源code提供了Adam、sgd和Adam_onecycle,adam似乎也是应用最广的优化器吧)
1 bgd 梯度下降
Batch Gradient Descent,将所有的数据集都载入,计算它们所有的梯度,然后沿着梯度相反的方向更新权重。缺点是计算量大,在一次更新中,就对整个数据集计算梯度,且逃不出鞍点,非凸函数会收敛到局部极小值。如何求损失函数梯度以及如何同时计算所有数据看这里。
https://www.cnblogs.com/leijing0607/p/7999541.html
2 sgd 随机梯度下降
Stochastic Gradient Descent,每次更新时对每个样本进行梯度更新。
缺点是更新比较频繁,loss震荡比较剧烈。优点是有震荡所以可以跳出局部极小值。
3 mbgd
Mini-batch gradient descent,每一次利用一小批样本,这样可以降低参数更新时的方差,收敛更稳定,另一方面可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。
1 Momentum
可以对SGD加速并减小震荡。
SGD 在 ravines 的情况下容易被困住, ravines 就是曲面的一个方向比另一个方向更陡,这时 SGD 会发生震荡而迟迟不能接近极小值(与海森矩阵有关)。这种情况相当于小球从山上滚下来时是在盲目地沿着坡滚,如果它能具备一些先知,例如快要上坡时,就知道需要减速了的话,适应性会更好。(没仔细看,之后找文章看下)
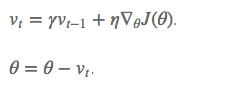
2 NAG
在计算梯度时,不是在当前位置,而是未来的位置上。
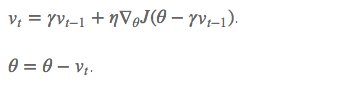
损失通常高度敏感于参数空间中的某些方向,而不敏感于其他。 动量算法可以在一定程度缓解这些问题,但这样做的代价是引入了另一个超参数。如果方向敏感度在某种程度是轴对齐的,那么每个参数设置不同的学习率,在整个学习过程中自动适应这些学习率是有必要的。
2 Adagrad
具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。对低频的参数做较大的更新,对高频的做较小的更新。因此,对于稀疏的数据的表现很好,很好地提高了 SGD 的鲁棒性。

2 Adadelta
对 Adagrad 的改进。
3 Adam
Adam一般来说是收敛最快的优化器,所以被用的更为频繁。
前两行是对梯度和梯度的平方进行滑动平均,使得每次的更新都和历史值相关。中间两行是对初期滑动平均偏差较大的一个修正,叫做 bias correction,t越来越大时,两个分母也趋于1。最后是参数更新公式。
使用Adam 这些自适应学习率的方法时,也要学习率衰减lr decay。


https://blog.csdn.net/qq_29462849/article/details/80626772
https://blog.csdn.net/weixin_41417982/article/details/81561210
学习率decay
optimizer
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

