公司新闻
为什么凸性是优化的关键
优化问题是机器学习的核心,而凸函数在优化中又起着重要的作用。
作者:NVS Yashwanth
编译:McGL
当你刚开始学习机器学习时,可能最有趣的就是优化算法,具体来说,就是梯度下降法优化算法,它是一个一阶迭代优化算法,用来使成本函数最小化。
梯度下降法背后的直觉是收敛到一个解,这个解可能是邻近区域的局部极小值,或者在最好的情况下是全局极小值。
一切看起来都很好,直到你开始质疑收敛问题。对凸性有一个很好的理解可以帮助你证明梯度下降法理论背后的直觉。因此,让我们讨论这个问题吧。
简单地说,可以把凸集想象成一种形状,其中任何连接2点的线都不会超出凸集。这叫做凸集。
看看下面的例子。
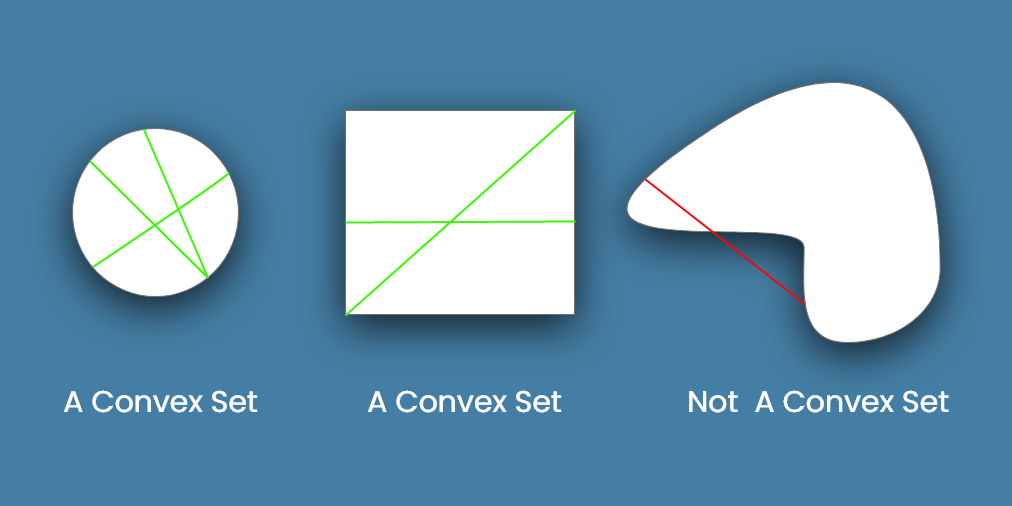
很明显,任意一条连接圆形或正方形(左边和中间的形状)上2个点的线段,都将包含在这个形状内。这些是凸集的例子。
另一方面,上图最右边的形状有一部分线段在形状外面。因此,这不是一个凸集。
一个凸集 C 可以表示如下。
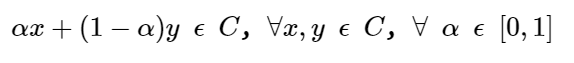
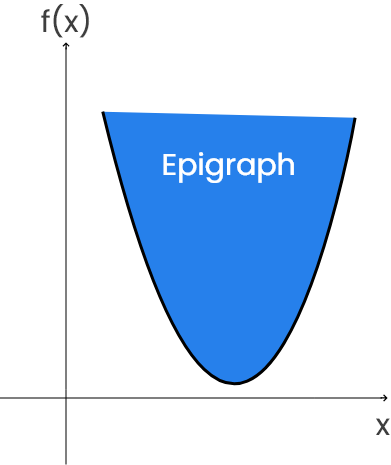
看下面函数 f 的图形。
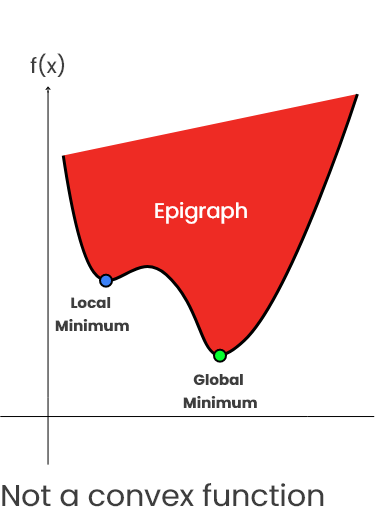
epigraph 是在函数中或其上的一组点。
好了,现在你们知道什么是凸集和 epigraph 了,我们可以讨论凸函数了。
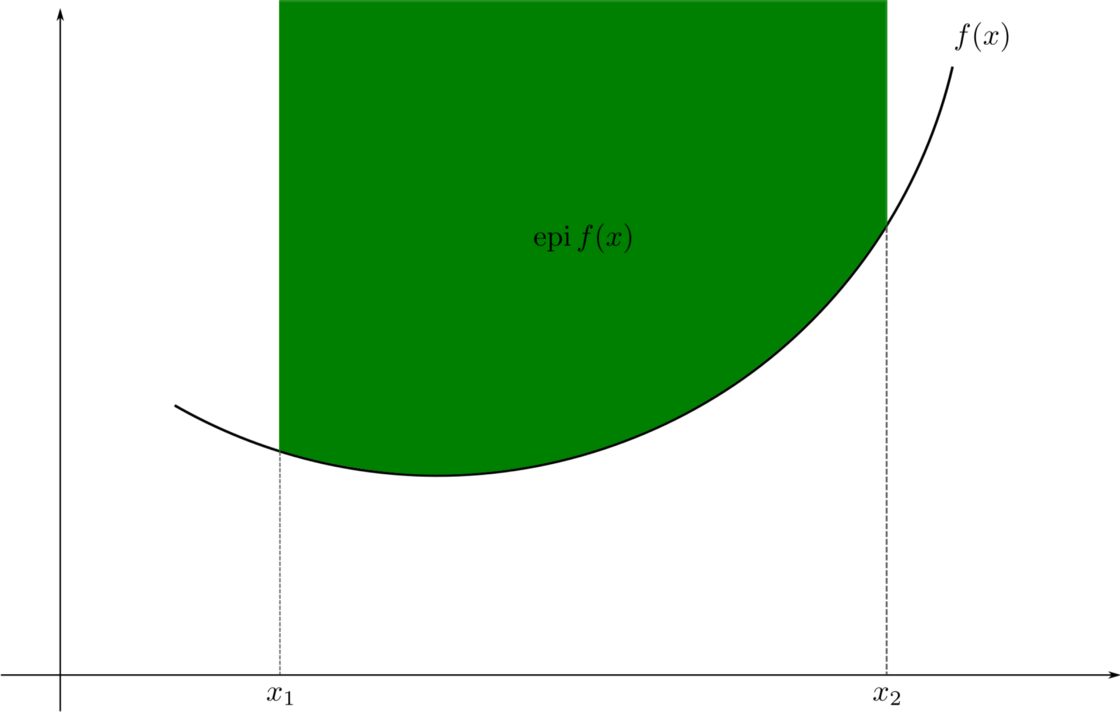
如果一个函数 f 的 epigraph 是凸集(如左下方绿色图所示)),则称该函数为凸函数。
这意味着在这个 epigraph 上画的每个两点间线段总是等于或高于函数图。暂停一分钟,自己检查一下。
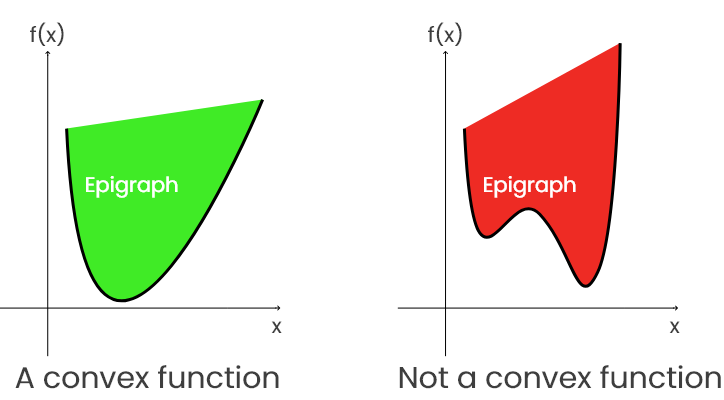
这意味着,如果存在两个点 x,y 使得连接 f(x)和 f(y)的线段低于函数 f 的曲线,则 f 不是凸的。这就导致了 epigraph 凸性的丧失(如上图右侧红色图形所示)。
这意味着在 epigraph 上绘制的每个线段并不总是等于或高于函数线。可以通过在弯曲处取点来证明。
在神经网络中,大多数的成本函数是非凸的。因此,必须测试函数的凸性。
如果函数 f 的二阶导数大于或等于0,则称该函数 f 为凸函数。
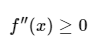
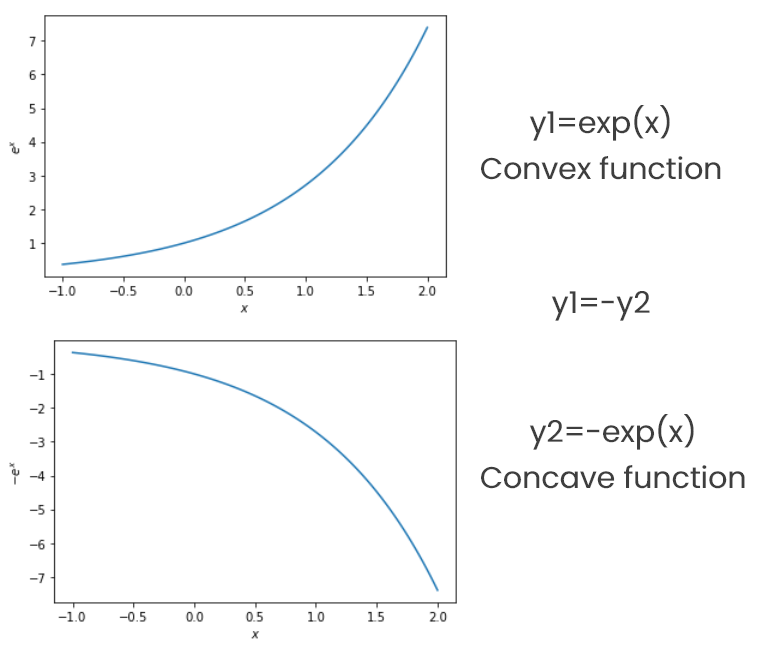
凸函数的例子: y=e?, y=x2。这两个函数都是二次可微的。
如果 -f(x) 是一个凸函数,那么函数 f 称为凹函数。
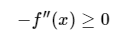
凹函数的例子: y=-e?。这个函数是二次可微的。
让我们通过绘制指数函数 e? 的图来检查凸性。
绘制凸函数和凹函数的代码:
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(-1, 2, 100)
# Convex function y1
y1 = np.exp(x)
plt.figure(1)
plt.plot(x, y1)
plt.xlabel('$x$')
plt.ylabel('$e^x$')
plt.show()
# Concave function y2
y2 = -np.exp(x)
plt.figure(2)
plt.plot(x, y2)
plt.xlabel('$x$')
plt.ylabel('$-e^x$')
plt.show()
view raw
代码输出:
如前所述,梯度下降法优化算法是一种一阶迭代优化算法,用于使成本函数最小化。
为了理解凸性如何在梯度下降法中发挥关键作用,让我们以凸和非凸成本函数为例讲解。
对于线性回归模型,我们定义了成本函数均方误差(MSE) ,它度量了实际值和预测值之间的平均方差。我们的目标是最小化这个成本函数,以提高模型的准确率。MSE 是一个凸函数(它是二次可微的)。这意味着没有局部极小值,只有全局极小值。因此,梯度下降法将会收敛到全局极小值。
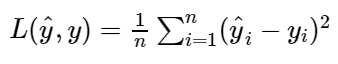
现在让我们考虑一个非凸的成本函数,在这种情况下,取一个任意的非凸函数,如下图所示。
你可以看到梯度下降法将停止在局部极小值,而不是收敛到全局极小值。因为这一点的梯度为零(斜率为0)且是附近区域的极小值。解决这个问题的一个方法是使用动量(momentum)。
凸函数在优化问题中起着重要的作用。优化是机器学习模型的核心。凸性因此也非常重要,相信看完这篇文章你已经理解的很清楚了。
谢谢。
来源:https://towardsdatascience.com/understand-convexity-in-optimization-db87653bf920
开丰新闻
联系我们
公司名称: 开丰娱乐-开丰五金配件机电公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

